1 概述
RT1052 FlexRam cache MPU FlexSPI
2 环境
《如何使用nxpcpress IDE.pdf》
3 不同
i.MX RT系列芯片内核是M7核,有一些独特的、与STM32 M3系列入门芯片不一样的高级的外设。
要熟练使用RT芯片,需要了解这些外设使用方法,否则会遇到一些迷惑的现象与BUG。
3.1 FlexRAM
参考《AN12077 Using the i.MX RT FlexRAM.pdf》、《AN12042 Using the i.MXRT L1 Cache.pdf》
不同型号的芯片RAM不一样,RT1052有512K,RT1015就只有128K。
FlexRAM,是灵活RAM的意思,可以将RAM切割为三部分,分别是:ITC/DTC/OC,在AN12077文档有说明如何切割。
itc,指令紧密耦合
dtc, 数据紧密耦合
OC,普通ram
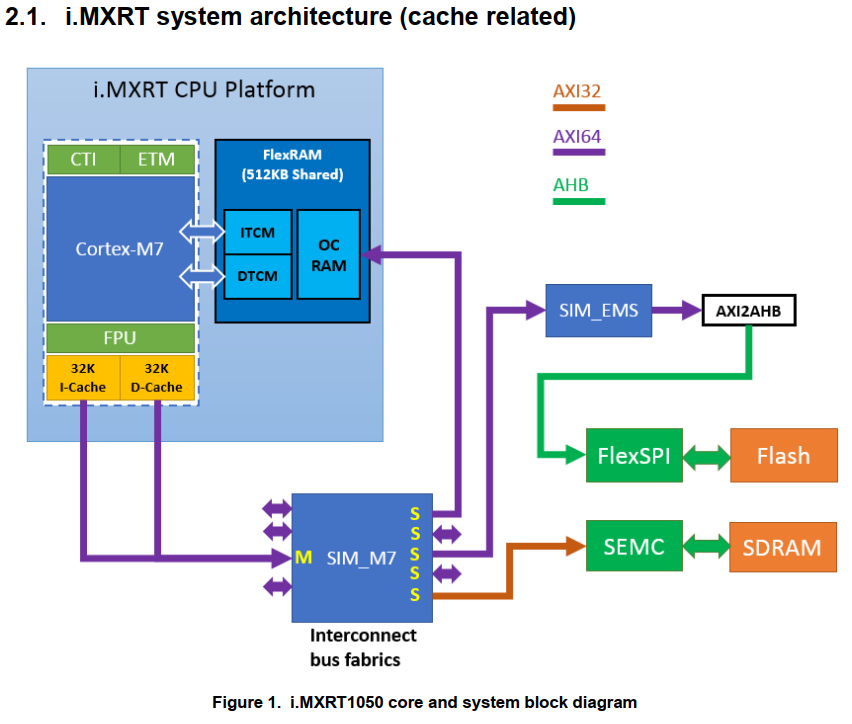
在AN12042文档中有下图,从图可以看出芯片数据和指令在存储和内核之间的传输通道,也即是芯片的内部总线。
从图中可得到以下信息:
- itcm和dtcm直接连接到M7内核,不经过cache。
- OC RAM会经过cache
- FlexSPI经过AHB总线,再经过AXI64总线,经过SIM_M7控制器,才进入内核
芯片启动时,执行默认的FlexRam分配。
如果你配置了efuse中关于FelxRAM的bit,芯片就会按照efuse切割。
如果不想配置efuse,我们还可以在代码中动态配置切割方式。
xvoid ResetISR(void) {< /pre>// Disable interrupts__asm volatile ("cpsid i");__asm volatile ("MSR MSP, %0" : : "r" (&_vStackTop) : );/* ref:AN12077 Using the i.MX RT FlexRAM.pdf》2.1.1.2. Runtime configuration* GPR17 (32KB per bank, every two bits means one bank)* 00 Not used* 01 OCRAM* 10 DTCM* 11 ITCMRT1015 have 4 banck0x5b(01011011) mean 64KB OCRAM, 32KB DTCM, 32KB ITCM*/IOMUXC_GPR->GPR17 = 0x0000005b;/* disbalbe config */IOMUXC_GPR->GPR16 &= ~IOMUXC_GPR_GPR16_INIT_ITCM_EN_MASK;IOMUXC_GPR->GPR16 &= ~IOMUXC_GPR_GPR16_INIT_DTCM_EN_MASK;/** GPR14 bit23-bit200000 0 KB (No DTCM)0011 4 KB0100 8 KB0101 16 KB0110 32 KB0111 64 KB1000 128 KB1001 256 KB1010 512 KB*/IOMUXC_GPR->GPR14 &= ~IOMUXC_GPR_GPR14_CM7_CFGDTCMSZ_MASK;IOMUXC_GPR->GPR14 |= IOMUXC_GPR_GPR14_CM7_CFGDTCMSZ(6);/** GPR14 bit19-bit160000 0 KB (No ITCM)0011 4 KB0100 8 KB0101 16 KB0110 32 KB0111 64 KB1000 128 KB1001 256 KB1010 512 KB*/IOMUXC_GPR->GPR14 &= ~IOMUXC_GPR_GPR14_CM7_CFGITCMSZ_MASK;IOMUXC_GPR->GPR14 |= IOMUXC_GPR_GPR14_CM7_CFGITCMSZ(6);/* see IOMUXC_GPR_GPR16_FLEXRAM_BANK_CFG_SEL */IOMUXC_GPR->GPR16 |= IOMUXC_GPR_GPR16_FLEXRAM_BANK_CFG_SEL_MASK |IOMUXC_GPR_GPR16_INIT_DTCM_EN_MASK |IOMUXC_GPR_GPR16_INIT_ITCM_EN_MASK;
上面代码是RT1015芯片例子,在启动函代码startup_mimxrt1015.c中,ResetISR函数最前面添加上面的代码,实现FlexRAM配置。
GPR17寄存器用于配置如何切割,这是1个32bit寄存器,1个bank使用2个bit配置,1个bank 32K,意味这最多可管理16 bank x 32K=512K。
上面代码配置为0x0000005b,也就是01-01-10-11,意味着将RAM切割为64KByte OCRAM, 32KByte DTCM, 32KByte ITCM。
配置完RAM切割后,再通过GPR14配置ITC和DTC的容量大小。
在代码中配置FlexRam,只是配置了硬件外设上FlexRAM如何分配。
还需要配置软件如何分配,修改代码编译链接时FlexRam的分配即可。
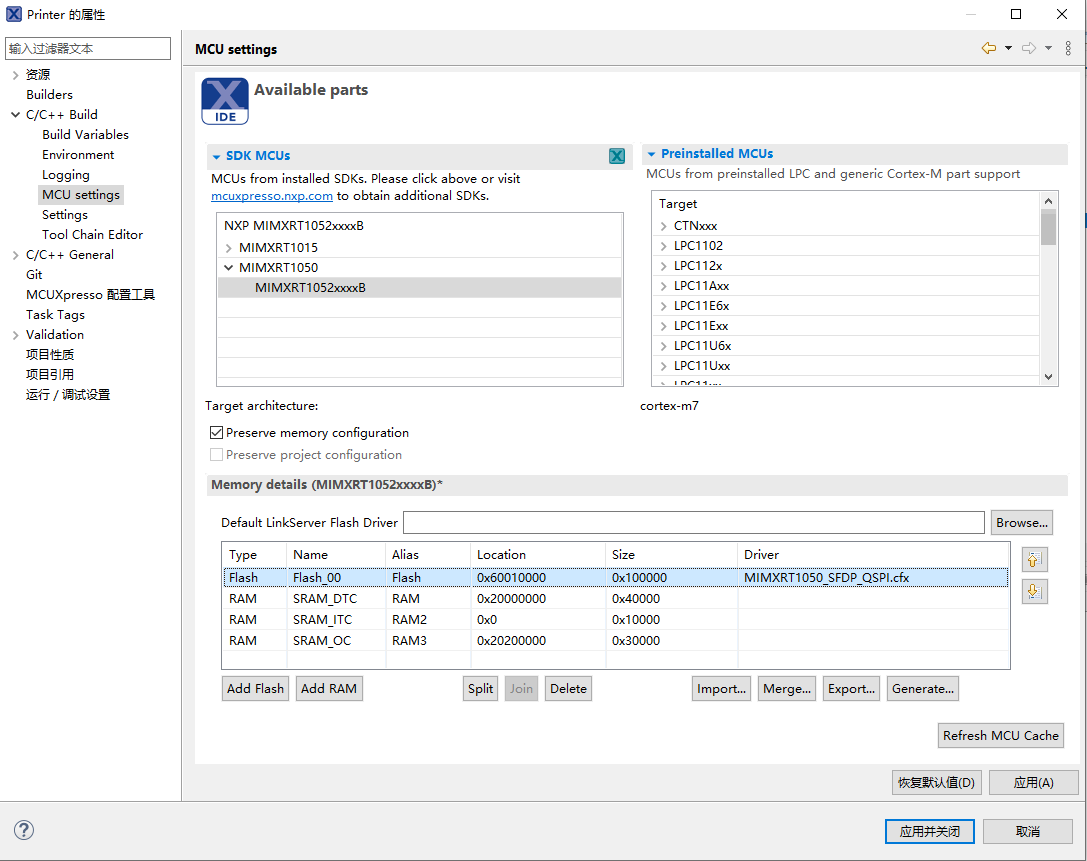
在IDE中配置,如下图,根据刚刚的配置修改Size。地址不要动。
还需要� �改默认栈的位置,默认放在end,需要改为Start,Size按照工程需要改,我这里的例子使用了rtos,所以堆和栈配置很小。
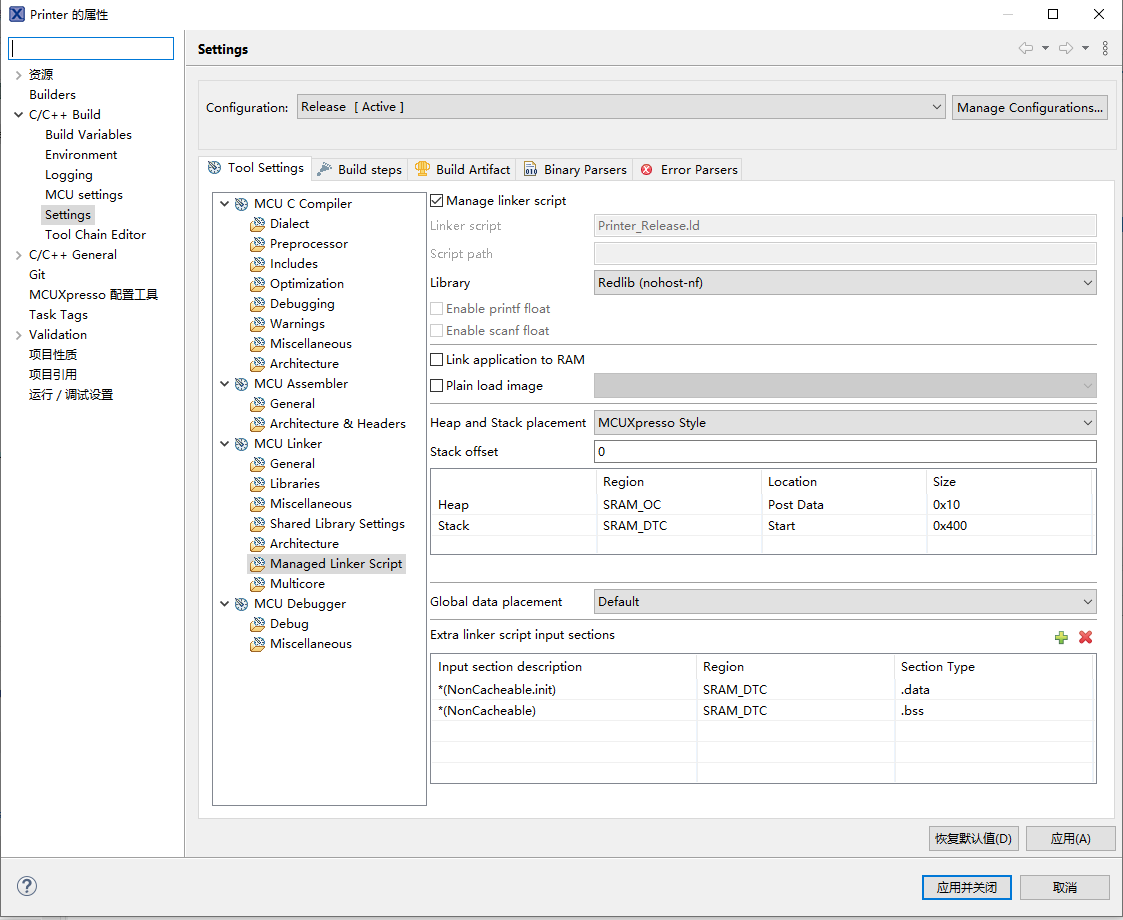
到此,FlexRam配置完成, 但是,还需要配置MPU,否则可能出现死机的情况
3.2 CACHE
参考《AN12042 Using the i.MXRT L1 Cache》
cache是什么?是一点小内存,在FlexRam一节中有一张图说明了芯片的总线结构。
从图中可见,在M7核中有两个cache:I-cache和D-chace。
cache有什么用呢?
cpu很快,很快。
外设很慢,很慢。比如存代码的Flash,即使是133M,要用QSPI通信才能读数据,所以,很慢很慢。
再两者之间加一小块高速的内存做cache,常用的指令或数据保存在cache,不用频繁从慢设备获取。
当然,cache是一个很复杂的功能,我们在此不讨论cache的实现,只是简单理解cache而已。
总之,cache相当于内核和外设(Flash 、OC ram)的中间缓冲,可以加快数据和指令的读取速度。
但是cache,会引入数据不同步问题:
最典型的就是在Flash上创建文件系统:
开始,我们读了Flash中的一块数据到OC RAM中,这时,在cache中,会临时保存这些数据。
然后通过FlexSPI接口修改了Flash中的数据,这时,就需要进行cache同步(清cache),否则程序还是使用cache中的旧数据。
使用另外一种方法:通过MPU配置将cache配置为直通模式。具体如何配置见MPU部分内容。
MPU
MPU主要有两部分配置:cache特性、空间管理。
空间,按照FlexRAM的分配设置。cache按需配置。
宏ARM_MPU_RBAR配置MPU区域和起始地址,总共可以配置16个区域,不同区域可重叠,具体见文档。
宏ARM_MPU_RASR配置cache属性和空间大小。ARM_MPU_RASR有8个参数,具体功能在代码中有详细说明,如下:
xxxxxxxxxx/*** MPU Region Attribute and Size Register Value** \param DisableExec Instruction access disable bit, 1= disable instruction fetches.* \param AccessPermission Data access permissions, allows you to configure read/write access for User and Privileged mode.* \param TypeExtField Type extension field, allows you to configure memory access type, for example strongly ordered, peripheral.* \param IsShareable Region is shareable between multiple bus masters.* \param IsCacheable Region is cacheable, i.e. its value may be kept in cache.* \param IsBufferable Region is bufferable, i.e. using write-back caching. Cacheable but non-bufferable regions use write-through policy.* \param SubRegionDisable Sub-region disable field.* \param Size Region size of the region to be configured, for example 4K, 8K.*/#define ARM_MPU_RASR(DisableExec, AccessPermission, TypeExtField, IsShareable, IsCacheable, IsBufferable, SubRegionDisable, Size)
我使用RT1015的MPU配置如下:
xxxxxxxxxx/* ARM_MPU_RASR(XN, AP, TEX, S, C, B, SRD, Size)XN 不能做指令访问AP 访问权限S 在i.MXRT 意味着non-cacheableTEX C B:决定cache策略0 1 0 narmal WT no WA0 1 0 narmal WB no WA1 1 1 narmal WB WA1 0 0 narmal no-cache只要配置为WB,就会有RAM同步问题。SRD是子区域,通常不用。Size是容量疑问:无论是ITCM还是DTCM,都是被Cache bypass的,SDK例程为什么要设置MPU呢?开发中发现,如果设置了,会造成各种意外异常,当然,可能是没设置好。ITCM和DTCM默认是normal设备类型,cache无效*//* 配置QSPI FLASH的Cache功能 */#if defined(XIP_EXTERNAL_FLASH) && (XIP_EXTERNAL_FLASH == 1)/* Region 3 setting: Memory with Normal type, not shareable, outer/inner write back. */MPU->RBAR = ARM_MPU_RBAR(2, 0x60000000U);MPU->RASR = ARM_MPU_RASR(0, ARM_MPU_AP_RO, 0, 0, 1, 1, 0, ARM_MPU_REGION_SIZE_16MB);#else/* Setting Memory with Device type, not shareable, non-cacheable. */MPU->RBAR = ARM_MPU_RBAR(2, 0x60000000U);MPU->RASR = ARM_MPU_RASR(0, ARM_MPU_AP_RO, 2, 0, 0, 0, 0, ARM_MPU_REGION_SIZE_64MB);#endif/* Region 4 setting: Memory with Device type, not shareable, non-cacheable. */MPU->RBAR = ARM_MPU_RBAR(4, 0x00000000U);MPU->RASR = ARM_MPU_RASR(0, ARM_MPU_AP_FULL, 2, 0, 0, 0, 0, ARM_MPU_REGION_SIZE_1GB);/* Region 5 setting: Memory with Normal type, not shareable, outer/inner write back配置ITC*/MPU->RBAR = ARM_MPU_RBAR(5, 0x00000000U);MPU->RASR = ARM_MPU_RASR(0, ARM_MPU_AP_FULL, 1, 0, 0, 0, 0, ARM_MPU_REGION_SIZE_32KB);/* Region 6 setting: Memory with Normal type, not shareable, outer/inner write back配置DTC*/MPU->RBAR = ARM_MPU_RBAR(6, 0x20000000U);MPU->RASR = ARM_MPU_RASR(0, ARM_MPU_AP_FULL, 1, 0, 0, 0, 0, ARM_MPU_REGION_SIZE_32KB);/* Region 7 setting: Memory with Normal type, not shareable, outer/inner write back配置OC*/MPU->RBAR = ARM_MPU_RBAR(7, 0x20200000U);MPU->RASR = ARM_MPU_RASR(0, ARM_MPU_AP_FULL, 0, 0, 1, 0, 0, ARM_MPU_REGION_SIZE_64KB);
代码Flash配置为:可代码执行,只读,使用cache,策略(0 1 1), NA,空间16M
ITC配置为: 可代码执行,只读,non-cacheable,策略(0 0 0), NA,空间32K
DTC配置为: 可代码执行,只读,non-cacheable,策略(0 0 0), NA,空间32K
OTC配置为: 可代码执行,只读,使用cache,策略(0 1 0), NA,空间64K
Flash,使用cache,提高代码执行速度。 ITC和DTC本身是被cache bypass的,配置为不用cache。
关键是OC,使用cache,但是配置为narmal WB no WA。
WT:write through
WB:write back
WA:write alloc
这种配置只有在使用FlexSPI修改Flash上的数据时,需要手动清cache,其他地方都不需要特殊处理。
当然,你也可以将配置按照你的需求分的更细一些。
XIP
xxxxxxxxxxconst flexspi_nor_config_t qspiflash_config = {.memConfig ={& nbsp; .tag = FLEXSPI_CFG_BLK_TAG,.version = FLEXSPI_CFG_BLK_VERSION,.readSampleClkSrc = kFlexSPIReadSampleClk_LoopbackFromDqsPad,/* 芯片类型 */.deviceType = kFlexSpiDeviceType_SerialNOR,.csHoldTime = 3u,.csSetupTime = 3u,/* 四线模式, 时钟100M,8M容量 */.sflashPadType = kSerialFlash_4Pads,.serialClkFreq = kFlexSpiSerialClk_80MHz,.sflashA1Size = 4u * 1024u * 1024u,.sflashA2Size = 4u * 1024u * 1024u,/* LUT 表, RT芯片根据表格配置FlexSPI */.lookupTable ={FLEXSPI_LUT_SEQ(CMD_SDR, FLEXSPI_1PAD, 0xEB, RADDR_SDR, FLEXSPI_4PAD, 0x18),; FLEXSPI_LUT_SEQ(DUMMY_SDR, FLEXSPI_4PAD, 0x06, READ_SDR, FLEXSPI_4PAD, 0x04),},},.pageSize = 256u,.sectorSize = 4u * 1024u,.blockSize = 64u * 1024u,.isUniformBlockSize = false,};
FlexSPI
芯片内部没有Flash,代码保存在外部FLASH,这片Flash,是否还能用来保存数据呢?
比如建立1个littfs文件系统?答案是 能。
完成以下配置即可:
配置好LUT列表,让FlexSPI知道如何通过FlexSPI 擦除/写 Flash。
将操作Flash的代码放到RAM中(ITC)。
读写接口清cache。
- FlexSPI基本
参考RM 26.5.3(芯片参考文档26.5.3章节,下同)
芯片有1个FlexSPI外设,2个通道,A和B,每个通道有两个片选,总共就有A1/A2/B1/B2四个片选。
并行模式,并行,A1和B1组成1个并行接口,A2和B2组合。
独立模式,4个片选独立。
同时只能操作1个外设。
FlexSPI支持XIP,在源文件evkbimxrt1050_flexspi_nor_config.c中配置外设信息,芯片内部的ROM BOOT根据这些信息配置FlexSPI,进行XIP启动。
FlexSPI其实有两种通道,IP Command and AHB Command,IP 是指我们通过FlexSPI控制外设,AHB是芯片内核自己控制外设。
- 用外部Flash做说明,IP就是我们代码使用Flexspi对Flash进行读操作,写操作,擦除操作。我们的代码完成完整的SPI通信过程。
- AHB则是芯片自动控制FlexSPI完成SPI流程。或者说,AHB就是memory map,将Flash映射到一段地址空间,代码可直接访问这段空间。具体操控外设由芯片内部设备完成,不需要代码参与。
- FlexSPI配置
芯片使用XIP运行代码,那么在执行到用户代码时,FlexSPI外设已经配置好了,只需要更新LUT即可。
调用FLEXSPI_UpdateLUT函数更新指令列表。
LUT表是1个数组,长度为64个U32。
4个U32组成1个LUT Sequence,也就是8个16bit组成1个seq。
1个16bit是1个Instruction,那么1个Sequence包含8个Instruction
1个Instruction由3� �分组成,cmd,pad,operand(op)
宏
FLEXSPI_LUT_SEQ(cmd0, pad0, op0, cmd1, pad1, op1)用于组成两条Sequencecmd是Flexspi定义的,不同的cmd后面跟的op意义不一样。
pad指明几线通信,SPI有1线,2线,4线
拿XIP配置的读指令来说明
FLEXSPI_LUT_SEQ(CMD_SDR, FLEXSPI_1PAD, 0xEB, RADDR_SDR, FLEXSPI_4PAD, 0x18), FLEXSPI_LUT_SEQ(DUMMY_SDR, FLEXSPI_4PAD, 0x06, READ_SDR, FLEXSPI_4PAD, 0x04),
CMD_SDR: 命令序列,后面跟的0XEB就是1个命令,这个命令就是Flash的读命令,这条seq用1线发送。
RADDR_SDR:发送读地址,OP是0x18,指明地址是24bit地址,传输地址到Flash使用4线模式。
DUMMY_SDR:发送dummy,OP是0x06,指明发送6个空闲时钟。
READ_SDR:读数据,使用四线模式,0x04好像没意义
从上可见,读Flash数据这条LUT Sequence,只使用了4条Instruction。
配置好LUT后,调用FLEXSPI_TransferBlocking函数即可实现对Flash的操作。
xxxxxxxxxxflashXfer.deviceAddress = address;flashXfer.port = port;flashXfer.cmdType = kFLEXSPI_Command;flashXfer.SeqNumber = 1;flashXfer.seqIndex = NOR_CMD_LUT_SEQ_IDX_WRITEENABLE;status = FLEXSPI_TransferBlocking(FLASH_HD_FLEXSPI, &flashXfer);if (status != kStatus_Success) {return status;}
address是外设的地址,A1的地址是0开始,A2的地址是0+A1的空间,这两个空间的大小可以在XIP配置中定义,ROM boot在XIP时将其配置到FlexSPI寄存器中。
port:挂在那个片选就用那个PORT
cmdType参考代码定义。
SeqNumber 指要执行的LUT seq数量,通常是1条。
seqIndex, 要执行的LUT在表格中的索引。
- 代码放到RAM
函数
在函数前添加宏__RAMFUNC(RAM2) ,将函数放到ITC中,工程配置RAM2要对应ITC。
如果在操作Flash时也需要执行的中断函数,也需要放到RAM,注意额,是所有调用的函数。
比如函数1需要在写FLASH是执行,函数1调用了函数2,那么这两个函数都需要放到RAM。
变量
不要用到const变量,这种变量是放在code 段中。
中断向量
中断向量表也要放到RAM
其他
如果程序使用了FreeRTOS,需要关调度。并且处理好RTOS管理中断。
- cache & 中断
xxxxxxxxxxportENTER_CRITICAL();SCB_CleanInvalidateDCache();//操作FlashSCB_CleanInvalidateDCache();portEXIT_CRITICAL();
在操作Flash前后清D cache,
并关中断,我使用了RTOS,在此仅进入了临界区,并不是所有中断都关掉。
我会梳理需要在此时也执行的中断,全部放到RAM。
- 多片外设地址
比如,我在FlexSPI_A上,挂了一片Flash,一片 PSRAM,在XIP中,我定义了两片外设的容量都是4M。
FlexSPI,使用映射模式(AHB Command)直接读写时,偏移地址是0x60000000。
通过FlexSPI外设操作时(IP Command),挂在A1上的芯片起始地址是0x0,挂在A2上的芯片起始地址是0x0+A1芯片容量。
在调用FLEXSPI_TransferBlocking函数时传的参数要对。
xxxxxxxxxxflashXfer.deviceAddress = address;flashXfer.port = port;flashXfer.cmdType = kFLEXSPI_Command;flashXfer.SeqNumber = 1;flashXfer.seqIndex = NOR_CMD_LUT_SEQ_IDX_ERASESECTOR;status = FLEXSPI_TransferBlocking(FLASH_HD_FLEXSPI, &flashXfer);
如上,如果操作A1上的Flash,address从0开始,port=kFLEXSPI_PortA1;
如果操作A2上的PSRAM,address要从4M开始,port=kFLEXSPI_PortA2;
其他
IAP
和常见的芯片IAP基本一致。先实现FlexSPI读写Flash,才能实现IAP。
下载代码可使用常见的Ymodme协议。
关键点:从boot跳到APP时,跳转指令会被优化掉,需要强制定义不优化。如下是MCUXpressoIDE的定义方式。
xxxxxxxxxx//-----------------------------------------------------------------------------// FUNCTION: JumpToUserApplication// SCOPE: Bootloader application system function// DESCRIPTION: The function startup user application// PARAMETERS: pointer on user vector table// RETURNS: function never go back//-----------------------------------------------------------------------------#pragma GCC push_options#pragma GCC optimize ("O0")void JumpToUserApplication(uint32_t userSP, uint32_t userStartup){// set up stack pointer__asm("msr msp, r0");__asm("msr psp, r0");// Jump to PC (r1)__asm("mov pc, r1");}#pragma GCC pop_options
跳到APP时:关中断、清Icache和Dcache,跳。
跳到APP后:重新执行启动代码,关中断,配置中断向量,开中断,执行APP
在linux中,uboot初始化芯片后,linux通常不会重新初始化。
我们这里,app相当与一个重新开始的独立程序,对芯片重新初始化,只是,代码的位置不一样。
boot代码:
xxxxxxxxxx__disable_irq();/* 清理D Cache, 清理FlexSPI缓存*/SCB_DisableICache();SCB_DisableDCache();SCB_CleanDCache();//Jump to user applicationJumpToUserApplication(spvalue, reseth);
app代码:
xxxxxxxxxx__disable_irq();SCB_CleanInvalidateDCache();SCB_InvalidateICache();/* 配置中断向量表位置 本工程把中断向量表搬到RAM*///SCB->VTOR = (APP_ADDR + QSPI_FLASH_BASE_ADDR);memcpy(&RamVectors[0], &g_pfnVectors[0], 256*4);SCB->VTOR = &RamVectors[0];/*配置中断优先级分组:16位优先级全部设置为抢断优先级 */NVIC_SetPriorityGrouping(((uint32_t)0x3));__enable_irq();
end